GPT-5.2 vs. GPT-5.1: The Leap from Chatbot to Professional Workmate
Yuna Huang,Marketing Curator
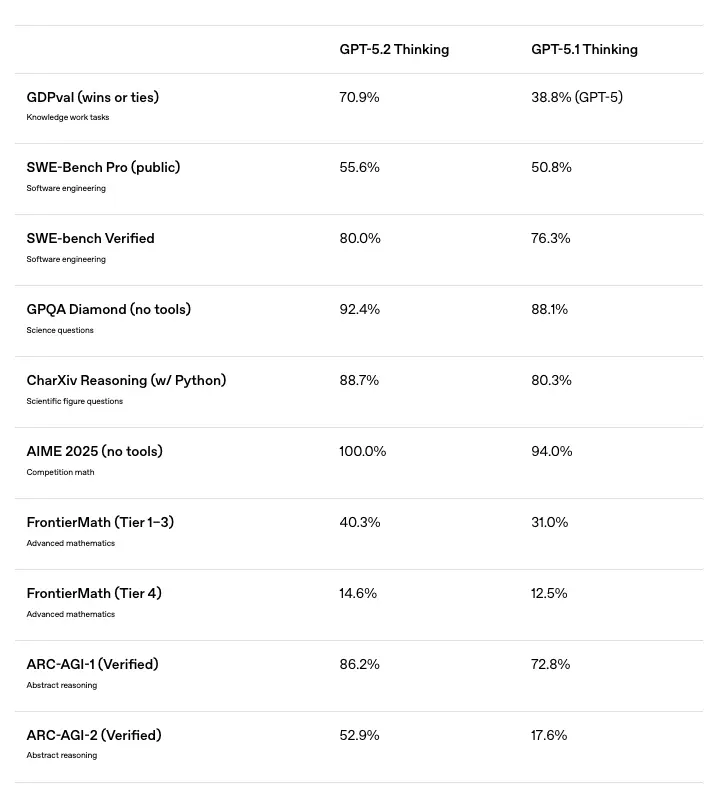
OpenAI has officially released GPT-5.2, marking a decisive shift from conversational AI to professional utility. While GPT-5.1 focused on making large language models warmer, more fluent, and easier to interact with, GPT-5.2 re-centers on hard reasoning, task execution, and economic output. With a 70.9% win rate against human experts on professional knowledge work (GDPval) and a 100% score on AIME 2025 math benchmarks, general model capability has reached a new ceiling. From this point forward, competitive advantage no longer comes from choosing a better model—but from domain-specific data quality, evaluation rigor, and how effectively teams operationalize these models in production.
GPT-5.2 vs. GPT-5.1: The Leap from Chatbot to Professional Workmate
On December 9, OpenAI officially deployed GPT-5.2, a release explicitly designed to be the "most capable model series yet for professional knowledge work." While the previous GPT-5.1 update focused on making the model warmer and more conversational, GPT-5.2 represents a tactical pivot back to hard logic, coding efficiency, and economic utility.
One look at the official benchmark report tells the whole story.
GPT-5.2 (left) vs GPT-5.1 (right): A generational leap.
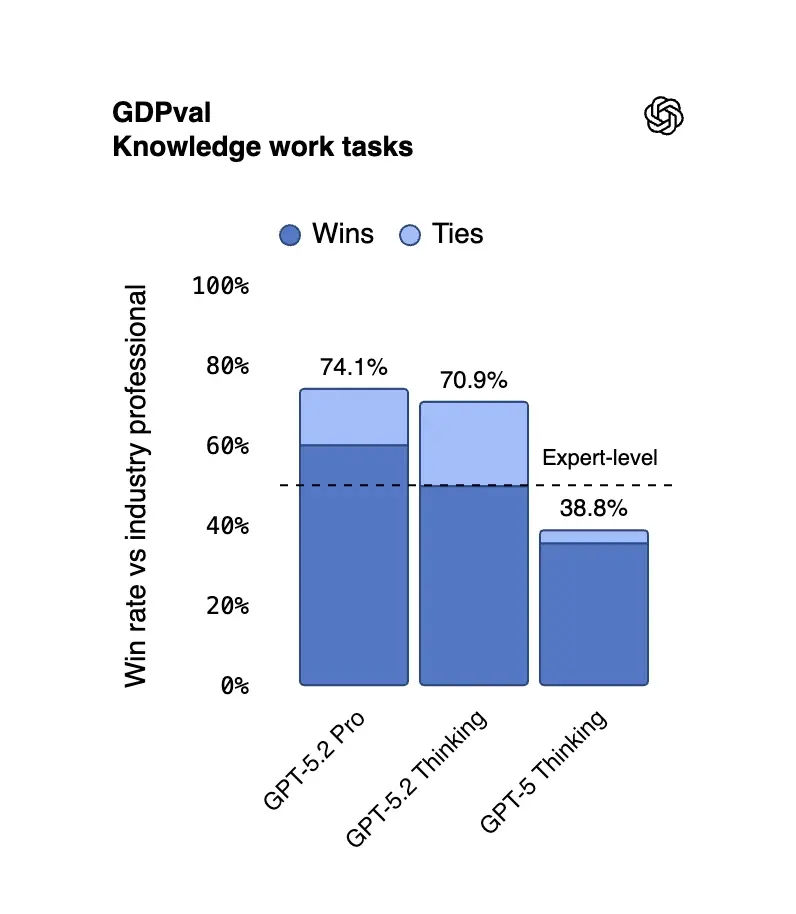
As the data shows, this is not a marginal upgrade. From a stunning 100% mastery of competition math (AIME 2025) to a massive jump in professional knowledge work (GDPval) from 38.8% to 70.9%, GPT-5.2 has systematically dismantled the ceiling set by its predecessor.
But beyond the impressive percentages, what does this new standard of "professional intelligence" actually mean for your engineering team, your product roadmap, and your data strategy? Let's dive into the details.
What does “Professional Intelligence” mean in GPT-5.2?
If GPT-5.1 was designed to be a better listener, GPT-5.2 is designed to be a better employee. OpenAI has explicitly positioned this release as the "most capable model series yet for professional knowledge work," and the numbers back up that claim.
GPT-5.2: Engineered for professional utility, not just chat.
The most telling metric comes from GDPval, a new benchmark that evaluates well-specified knowledge work across 44 distinct occupations.
In blind evaluations, GPT-5.2 beats or ties human professionals 70.9% of the time.
These are not open-ended chat prompts—they are structured tasks like:
The key shift: the model is no longer describing work—it is completing it, and doing so at roughly an order of magnitude faster than a human expert.
How big is the jump in coding capabilities?
For engineering teams, the upgrade is substantial. While GPT-5.1 was competent, GPT-5.2 pushed into expert territory.
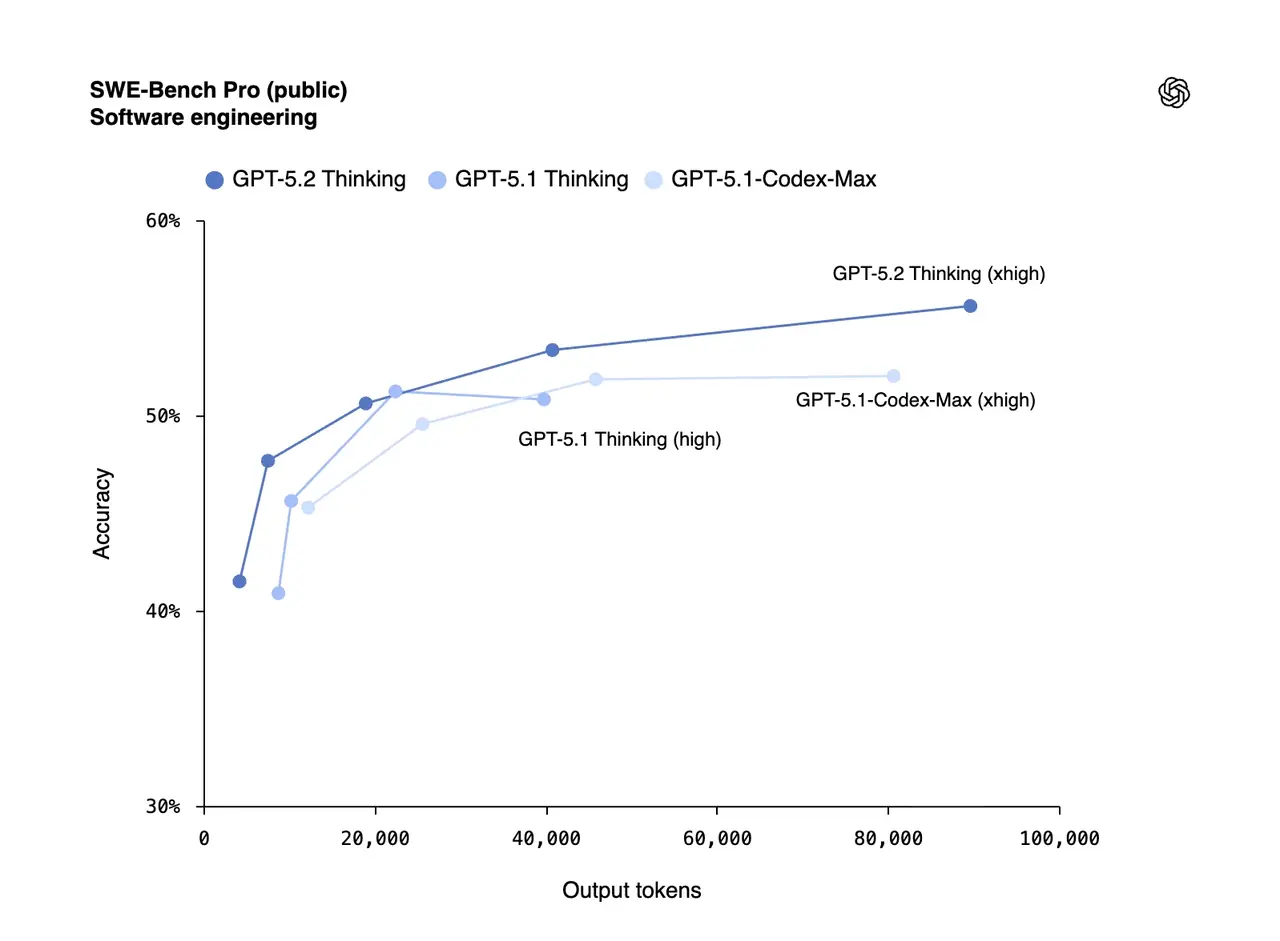
GPT-5.2 hits 55.6% on SWE-Bench Pro
SWE-Bench Pro: 55.6% (up from 50.8%)
SWE-Bench Verified: 80.0%
But benchmarks only tell part of the story. Early testers like JetBrains and Cognition point to a deeper capability: long-horizon agentic coding.
GPT-5.2 can:
Refactor large, interdependent codebases
Track architectural intent across files
Maintain coherence over multi-step implementation plans
This is the first GPT release where “one-shot coding” stops being the goal—system-level task ownership becomes realistic.
Can we finally trust AI with massive documents?
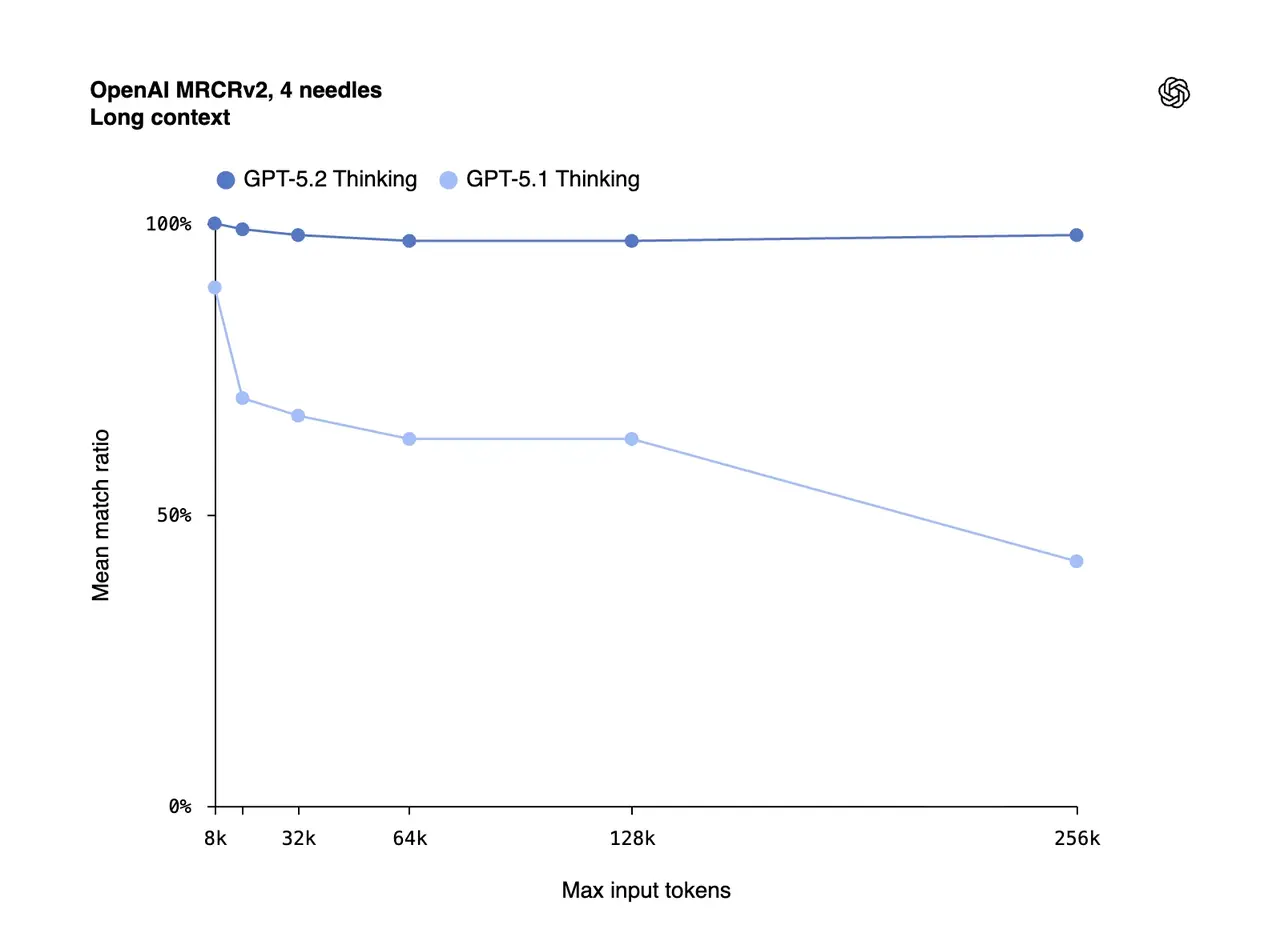
Reliability has always been the Achilles' heel of Large Language Models—until now. OpenAI focused heavily on "factuality" for this release, resulting in a 30% reduction in response-level errors compared to GPT-5.1.
GPT-5.2 achieved near 100% accuracy on retrieval tasks extending out to 256k tokens On MRCRv2
Key improvements:
30% reduction in response-level factual errors vs. GPT-5.1
Near-perfect accuracy on MRCRv2 retrieval tasks up to 256k tokens
For enterprise RAG systems, this is a turning point.
GPT-5.2 no longer “forgets” critical information buried mid-document—making it viable for:
Legal analysis
Scientific literature synthesis
Deep technical documentation workflows
Is your data ready for the GPT-5.2 era?
This release confirms a critical reality for 2026: Algorithms are converging, but data is the differentiator.
A model with 100% math accuracy and professional-grade reasoning is only as powerful as the information you feed it. If your internal documentation is messy, or your evaluation benchmarks are outdated, GPT-5.2 will merely hallucinate with greater confidence.
How Abaka AI helps teams operationalize GPT-5.2
At Abaka AI, we help forward-thinking teams bridge the gap between frontier models and production reality:
Benchmarking & Evaluation: We use rigorous open-source standards (like OmniDocBench from our 2077AI community) to verify if your models perform accurately on proprietary documents.
Agentic Data Curation(https://www.abaka.ai/blog/verigui-trustworthy-agent-data): We curate the complex, multi-turn "trajectory data" needed to fine-tune agents that can actually leverage GPT-5.2's advanced tool-use capabilities.
Expert Annotation: From complex math to specialized code, we provide the high-fidelity ground truth needed to customize these models for your specific industry.
What is the biggest difference between GPT-5.2 and GPT-5.1?
GPT-5.2 is optimized for professional task execution, not conversation quality. While GPT-5.1 focused on being more natural and friendly, GPT-5.2 prioritizes logic density, reliability, and structured output—making it suitable for real knowledge work rather than chat-based assistance.
Is GPT-5.2 ready for enterprise and production use?
Yes. GPT-5.2 shows a ~30% reduction in factual errors and maintains high accuracy across long-context documents (up to 256k tokens), enabling reliable use in enterprise RAG systems, legal analysis, and technical workflows.
Why does GPT-5.2 change the importance of data quality?
As general model capability converges, data—not algorithms—becomes the primary differentiator. GPT-5.2’s strong reasoning amplifies both good and bad inputs, meaning poorly structured or outdated data will lead to confident but incorrect outputs.
How should teams prepare to fully leverage GPT-5.2?
Teams need domain-specific datasets, rigorous evaluation benchmarks, and agentic trajectory data. Without these, GPT-5.2’s professional reasoning and tool-use capabilities cannot be reliably translated into production value.
What's your data bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.