Google Unveils VISTA: A Self-Improving AI Agent That Outperforms Baseline Video Prompts
Yuna Huang,Marketing Curator
Google has recently introduced VISTA (Video Iterative Self-improvemenT Agent), a revolutionary test-time self-improving agent for video generation. Rather than just being a new model, VISTA acts as a multi-agent loop that iteratively refines prompts and outputs to solve persistent issues like poor instruction following and physical inconsistency. For enterprises seeking production-grade AI, VISTA proves that superior output depends on a structured data feedback loop—the exact foundation provided by Abaka AI.
Google Unveils VISTA: The Self-Improving Agent for Flawless Video Generation
In the rapidly advancing field of text-to-video generation, models like Google's Veo 3 can produce stunningly high-quality video and audio. However, a critical challenge remains: the output quality is highly sensitive to the exact phrasing of the prompt. A user's intent can be lost, and physical or contextual alignment can drift, forcing a manual, time-consuming process of trial and error.
To solve this, Google AI has introduced VISTA (Video Iterative Self-improvemenT Agent), a groundbreaking framework that reframes video generation as a test-time optimization problem. Instead of being a new video model itself, VISTA is a "black-box" multi-agent loop that works on top of existing models (like Veo 3) to iteratively improve prompts and regenerate videos until the output is flawless.
The Death of "One-Shot" AI: Why Google VISTA is the Only Way to Survive 2026
In the brutal 2026 AI landscape, "stunning visuals" from models like Google Veo 3 are no longer a competitive advantage — they are the bare minimum. If your team is still trapped in the "Black Box" of manual prompt engineering, hoping for a lucky generation, you aren't building a product; you’re gambling with your compute budget. Manual trial-and-error is now an obsolete hobby, not a business strategy.
VISTA (Video Iterative Self-improvemenT Agent) has officially killed the "one-shot" generation myth. By reframing video production as a ruthless test-time optimization problem, VISTA eliminates the guesswork that plagues your competitors. It doesn't "hope" for a good video; it observes, critiques, and hunts down failures with surgical precision, regenerating until the output is flawless. In 2026, you either integrate agentic feedback loops like VISTA, or you settle for mediocre, unaligned outputs that the market will simply ignore.
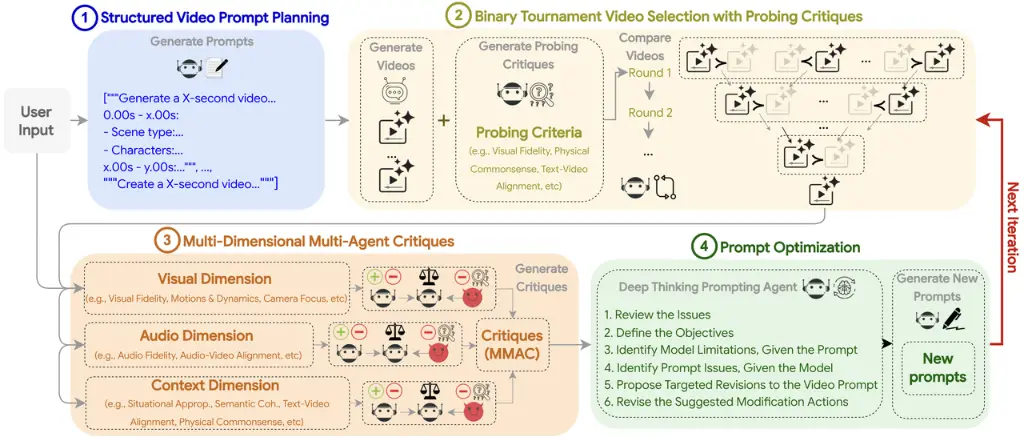
How VISTA Works: A 4-Step Iterative Loop
VISTA’s core innovation is its systematic, multi-agent approach to prompt refinement. The system jointly targets three aspects of quality: visuals, audio, and context. It achieves this through a continuous 4-step cycle.
Google VISTA's four-stage multi-agent loop: Planning, Selection, Critiques, and Optimization.
First, VISTA takes a simple user prompt and decomposes it into one or more timed "scenes." A multimodal LLM then enriches each scene with nine specific properties:
This structured plan acts as a detailed blueprint for the video generation model, enforcing constraints on realism and relevancy from the start.
Step 2: Pairwise Tournament Selection
Using the structured prompt, the system samples multiple video-prompt pairs. An MLLM "judge" then forces these candidates to compete in a binary tournament, using bidirectional swapping to reduce order bias. This "survival of the fittest" process selects a "champion" video based on criteria like visual fidelity, physical commonsense, and text-video alignment.
Step 3: Multi-Dimensional, Multi-Agent Critiques
The champion video and its prompt are then passed to a panel of specialized AI judges for a deep critique. This isn't just one judge; it's a triad of agents for each of the three dimensions (Visual, Audio, and Context):
Normal Judge: Provides a standard quality score.
Adversarial Judge: Actively tries to find failures and errors.
Meta Judge: Consolidates both critiques into a final, actionable report with scores from 1 to 10.
This multi-dimensional process allows the system to pinpoint targeted errors, such as poor temporal consistency, incorrect audio-video alignment, or a lack of physical commonsense.
Step 4: The Deep Thinking Prompting Agent
Finally, a "Deep Thinking Prompting Agent" analyzes the detailed critiques from Step 3. It runs a 6-step introspection to understand what went wrong, separate model limitations from prompt issues, and propose specific modification actions. It then intelligently rewrites the structured prompt to fix the identified flaws, and the entire cycle begins again.
Results: The Power of Iterative Refinement
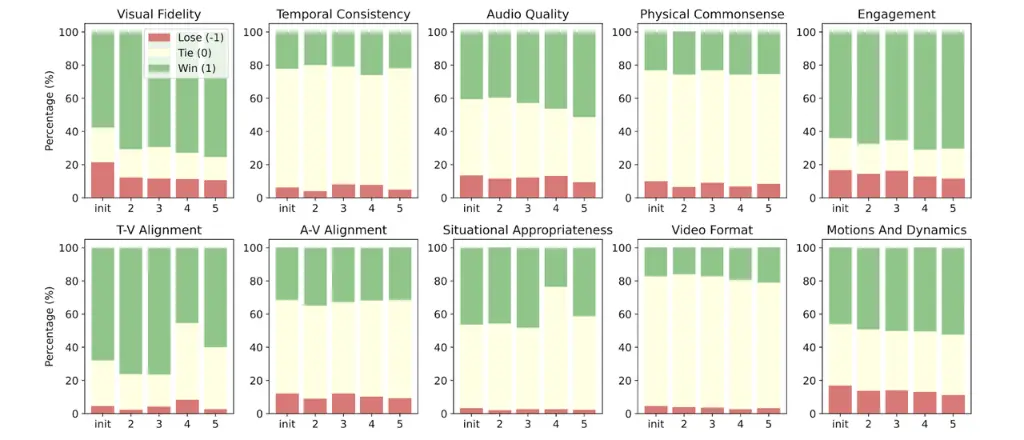
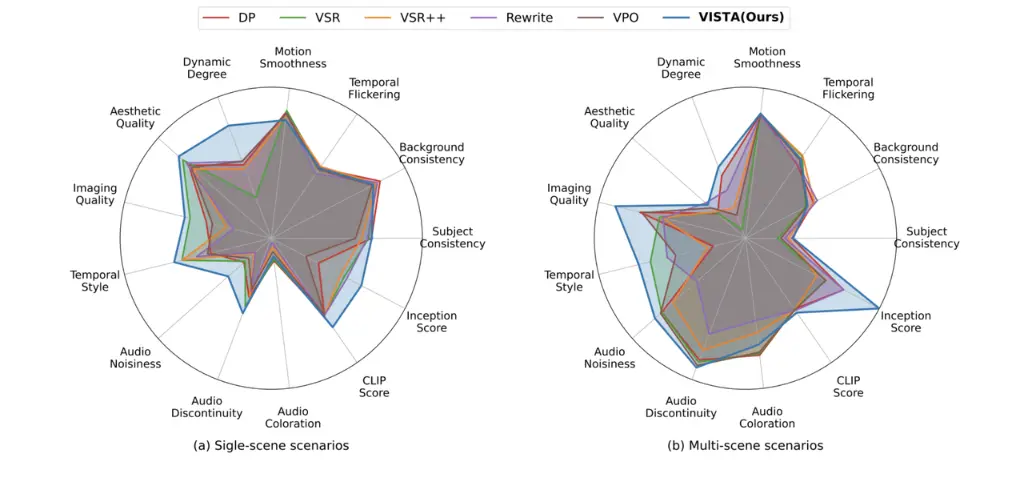
VISTA's (green) win rate over Direct Prompting (red) consistently improves across iterations on key quality metrics like fidelity and common sense.VISTA (blue) outperforms all other prompting baselines across a wide range of metrics in both single-scene (a) and multi-scene (b) benchmarks.
Data from the Google VISTA research demonstrates a clear advantage over traditional one-shot prompting methods:
Automatic Evaluation: VISTA achieves a win rate of up to 46.3% over direct prompting in multi-scene scenarios after five iterations.
Human Studies: The results are even more definitive. Human raters with prompt optimization experience preferred VISTA's output 66.4% of the time in head-to-head trials against the strongest baseline.
Why High-Quality Data is the Shared Language of VISTA and Abaka AI
VISTA is a practical and powerful step toward reliable AI generation. It proves that even the most advanced frontier models are not "one-shot" solutions. Achieving truly high-quality, reliable, and aligned AI output requires a structured, iterative, and critical process — one that can plan, execute, evaluate, and self-correct.
This is the exact philosophy that drives Abaka AI.
Just as VISTA requires a 9-attribute structured prompt to guide its generation agents, all sophisticated AI systems require a high-quality, structured data foundation to perform reliably in the real world. A model is only as good as the data it learns from.
Abaka AI is the architect of this foundation. We provide:
Expert-Level Mathematical & Code Datasets: Fueling the logical reasoning required for complex agents.
Verifiable Agentic Datasets: Utilizing our VeriGUI platform to build multi-step verification chains, eliminating model hallucinations.
Licensed High-Res Assets: With 1.2 billion videos and 960 million images, we provide the ethical, high-fidelity raw data needed for frameworks like VISTA to thrive.
The launch of VISTA shows that the future of AI is not just about bigger models, but about smarter, self-improving processes. Contact Abaka AI today to build the data-first foundation that will make your AI systems truly mission-ready.
FAQ: Everything You Need to Know About Google VISTA
Q1: Is Google VISTA a new video generation model? No, VISTA is a Test-time Self-improving Framework. It acts as an agentic layer on top of existing models like Veo 3 to optimize outputs through prompt iteration.
Q2: What is "Test-time Optimization" in the context of VISTA? It refers to the process of improving quality during the generation phase (at runtime) through feedback loops, rather than retraining the base model parameters.
Q3: How does VISTA improve "Abaka Alignment" and intent? By using Adversarial Judges and a Deep Thinking Agent, VISTA identifies where the video drifted from the user's original intent and corrects the underlying prompt structure to bring the model back into alignment.
What's your data bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.