
OmniDocBench was selected as the core benchmark by DeepSeek-AI’s new DeepSeek-OCR paper. Discover why our benchmark is the new industry standard for Document AI.
Blogs
2025-10-31/General
DeepSeek Chooses OmniDocBench: Our Benchmark Just Became the Industry Standard

Yuna Huang,Marketing Curator
DeepSeek Chooses OmniDocBench: Our Benchmark Just Became the Industry Standard
In the fast-paced world of AI research, validation is everything. How do you prove that your new, groundbreaking model is truly state-of-the-art? You test it against the hardest, most comprehensive benchmark you can find.
That’s why we’re thrilled to announce that DeepSeek-AI has selected 2077AI's OmniDocBench as a core evaluation benchmark for their revolutionary new paper, "DeepSeek-OCR: Contexts Optical Compression."
This isn't just a casual citation; it's a powerful statement. When a leading team like DeepSeek needs to prove the efficiency and power of their novel architecture, they turn to OmniDocBench. This confirms what we knew when we built it: OmniDocBench is quickly becoming the new industry standard for Document AI evaluation.

The Challenge: Why DeepSeek Needed OmniDocBench
DeepSeek's latest paper introduces a fascinating concept: using "optical 2D mapping" to highly compress long text contexts. Their goal is to create an OCR model that is not only highly accurate but also incredibly efficient, using a minimal number of "vision tokens."
This created a specific challenge:
They needed to prove their model was accurate on complex, real-world documents.
They needed to prove their model was efficient, outperforming others that use far more resources.
This is precisely the problem OmniDocBench was designed to solve.
As the DeepSeek paper states in its abstract:
"On OmniDocBench, it surpasses GOT-OCR2.0 (256 tokens/page) using only 100 vision tokens, and outperforms MinerU2.0 (6000+ tokens per page on average) while utilizing fewer than 800 vision tokens."
This single chart tells the whole story. DeepSeek-OCR achieves top-tier accuracy (low Edit Distance) while living in the "low token" zone on the right. In contrast, many other powerful models like MinerU2.0 are clustered on the far left, requiring over 6,000+ vision tokens to perform at a similar level.
OmniDocBench was the only benchmark that provided the granularity and real-world complexity needed to demonstrate this groundbreaking efficiency.
What Makes OmniDocBench the New "Proving Ground"?
Why did DeepSeek choose OmniDocBench over simpler, older benchmarks? Because Document AI in 2025 is about more than just reading clean, single-column academic papers.
The real world is messy. Our benchmark, OmniDocBench, was built to reflect such reality.
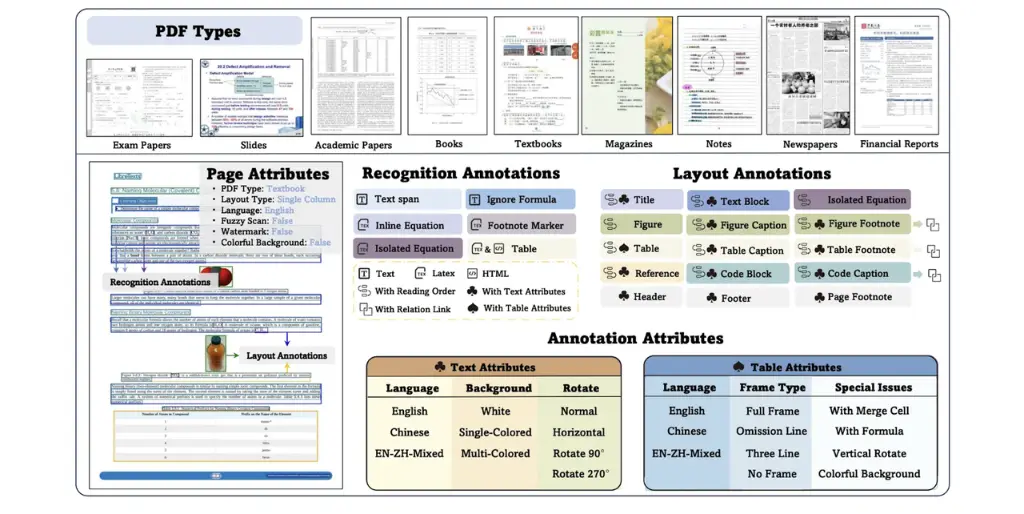
Unmatched Diversity (9 Types): While other benchmarks focus on one or two document types, OmniDocBench includes 9, featuring notoriously difficult categories like:
Financial Reports (dense tables)Handwritten Notes (messy text)Newspapers (complex multi-column layouts)Textbooks (intricate formulas and diagrams)Exam Papers & Slides
Fine-Grained Evaluation: We don't just give a single pass/fail score. OmniDocBench provides multi-level evaluations across 19 layout categories and 15 attribute labels. This allows researchers to pinpoint exactly where their model excels or fails—whether it's on tables, formulas, or rotated text.
Real-World Complexity: Our benchmark tests everything from layout analysis and OCR to table recognition and reading order estimation, providing a holistic "acid test" for any true end-to-end Document AI model.
Its diversity brings complex evaluation challenges, as different models have different strengths. Our own benchmark results clearly demonstrate this:
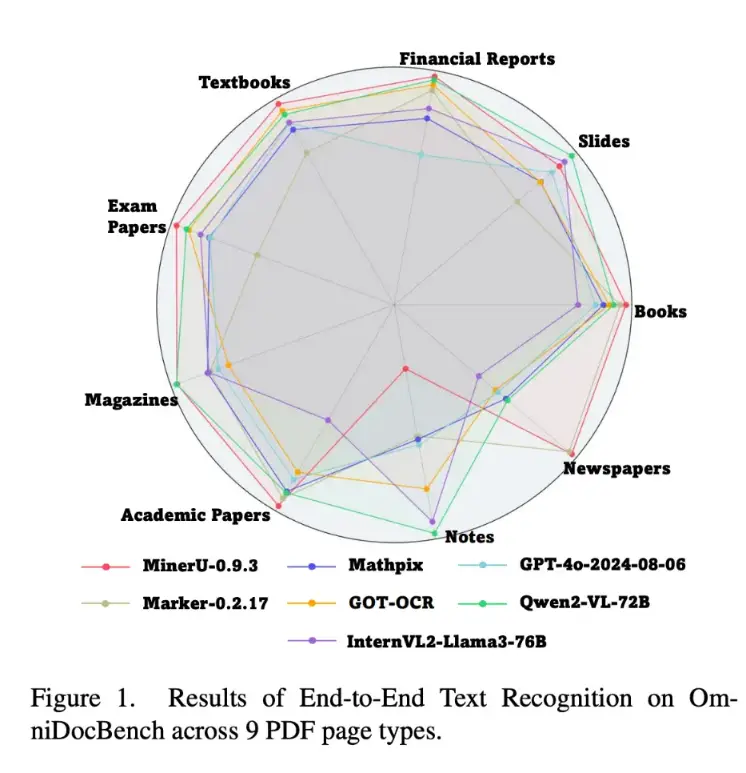
As the chart shows, no single model can conquer all categories. Some (like MinerU-0.9.3) excel at academic papers but fail at notes, while others have different profiles. This is why a simple "overall score" on a single document type is no longer enough to measure true capability.
How an Industry Standard is Built
Crafting a benchmark for this complex and reliable is a massive engineering feat. It requires a systematic, multi-stage process to ensure every data point is accurate.
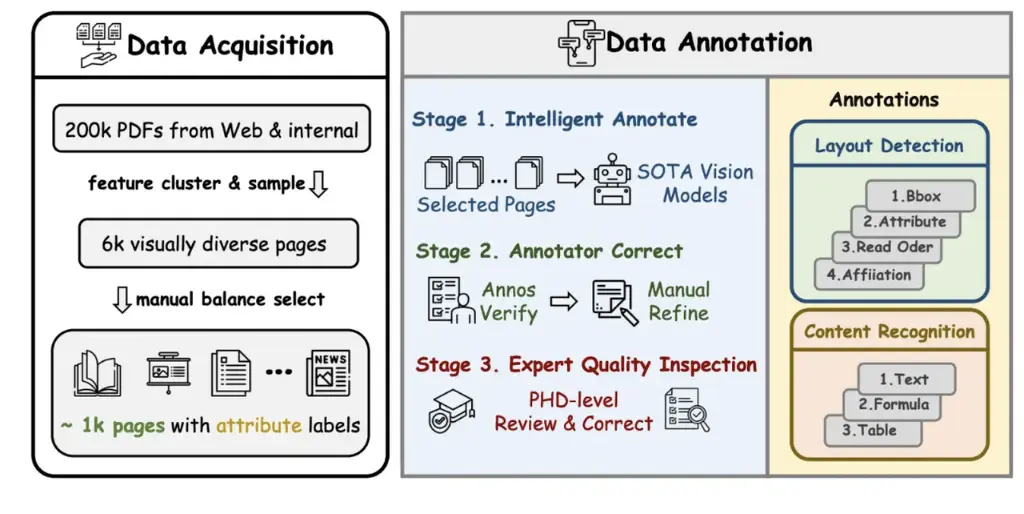
Our three-stage process—Intelligent Annotate, Annotator Correct, and Expert Quality Inspection—ensures that the final benchmark is precise, comprehensive, and ready to challenge the world's best models. We’re incredibly proud of this validation and congratulate the DeepSeek-AI team on their fantastic research. This achievement highlights a core philosophy of 2077AI: great AI is built on great data.
The creation of complex, high-fidelity benchmarks like OmniDocBench is a massive undertaking. It is powered by the cutting-edge data construction and annotation capabilities of our entire ecosystem, including our core contributors to Abaka AI. This validation from DeepSeek proves that the advanced data engineering pipelines we've built are setting the new industry standard.
2077AI and our partners will continue to build high-quality benchmarks that push the entire field of artificial intelligence forward.
🔗 Explore Research & Data
OmniDocBench Tech Blog: https://www.2077ai.com/blog/OmniDocBench
OmniDocBench Paper: https://arxiv.org/abs/2510.11652
Hugging Face Dataset: https://huggingface.co/datasets/Quivr/OmniDocBench
DeepSeek-OCR Paper: https://arxiv.org/html/2510.18234v1
What's your data
bottleneck this quarter?

Missing data
'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20id='Vector_2'%20d='M6.5%202.70833L10.2917%206.5L6.5%2010.2917'%20stroke='var(--stroke-0,%20white)'%20stroke-width='1.08333'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3c/svg%3e)
We collect it.
'%3e%3cpath%20d='M9.62284%201.63478C9.42742%201.54564%209.21513%201.49951%209.00034%201.49951C8.78555%201.49951%208.57326%201.54564%208.37784%201.63478L1.95034%204.55978C1.81725%204.61846%201.7041%204.71458%201.62466%204.83642C1.54522%204.95827%201.50293%205.10058%201.50293%205.24603C1.50293%205.39148%201.54522%205.53379%201.62466%205.65564C1.7041%205.77748%201.81725%205.8736%201.95034%205.93228L8.38534%208.86478C8.58076%208.95392%208.79305%209.00005%209.00784%209.00005C9.22263%209.00005%209.43492%208.95392%209.63034%208.86478L16.0653%205.93978C16.1984%205.8811%2016.3116%205.78498%2016.391%205.66314C16.4705%205.54129%2016.5127%205.39898%2016.5127%205.25353C16.5127%205.10808%2016.4705%204.96577%2016.391%204.84392C16.3116%204.72208%2016.1984%204.62596%2016.0653%204.56728L9.62284%201.63478Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%209C1.49965%209.14345%201.54044%209.28399%201.61754%209.40496C1.69464%209.52593%201.80482%209.62225%201.935%209.6825L8.385%2012.615C8.5794%2012.703%208.79035%2012.7486%209.00375%2012.7486C9.21715%2012.7486%209.4281%2012.703%209.6225%2012.615L16.0575%209.69C16.1903%209.63033%2016.3028%209.53332%2016.3814%209.4108C16.4599%209.28828%2016.5012%209.14555%2016.5%209'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M1.5%2012.75C1.49965%2012.8935%201.54044%2013.034%201.61754%2013.155C1.69464%2013.2759%201.80482%2013.3723%201.935%2013.4325L8.385%2016.365C8.5794%2016.453%208.79035%2016.4986%209.00375%2016.4986C9.21715%2016.4986%209.4281%2016.453%209.6225%2016.365L16.0575%2013.44C16.1903%2013.3803%2016.3028%2013.2833%2016.3814%2013.1608C16.4599%2013.0383%2016.5012%2012.8955%2016.5%2012.75'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-messy-data'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
Messy data
We label it.
'%3e%3cpath%20d='M9%2016.5C13.1421%2016.5%2016.5%2013.1421%2016.5%209C16.5%204.85786%2013.1421%201.5%209%201.5C4.85786%201.5%201.5%204.85786%201.5%209C1.5%2013.1421%204.85786%2016.5%209%2016.5Z'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3cpath%20d='M9%204.5V9L12%2010.5'%20stroke='%23FF8904'%20stroke-width='1.5'%20stroke-linecap='round'%20stroke-linejoin='round'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip-no-time'%3e%3crect%20width='18'%20height='18'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.
What's your data
bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have it Off-The-Shelf.
Pick the closest fit, we'll take the call from there.