5 Key Considerations for US Developers Choosing an OTS Dataset
Josephine Ongko Wijono,VP of Commercial Strategy
Choosing the wrong OTS dataset will cost you far more later — in model drift, re-training cycles, hallucination control, and poor real-world automation. In this article, we break down the 5 most important strategic factors US developers must consider when evaluating any third-party dataset provider.
5 Key Considerations for US Developers Choosing an OTS Dataset
Developer evaluating AI dataset options using a comparison dashboard interface
As the industry heads toward more autonomous, agent-like, workflow-coordinating AI systems — US developers are increasingly relying on OTS datasets to speed iteration and reduce heavy manual data engineering.
But with hundreds of vendors and wildly different quality levels, selecting OTS data is now a strategic decision, not a price comparison.
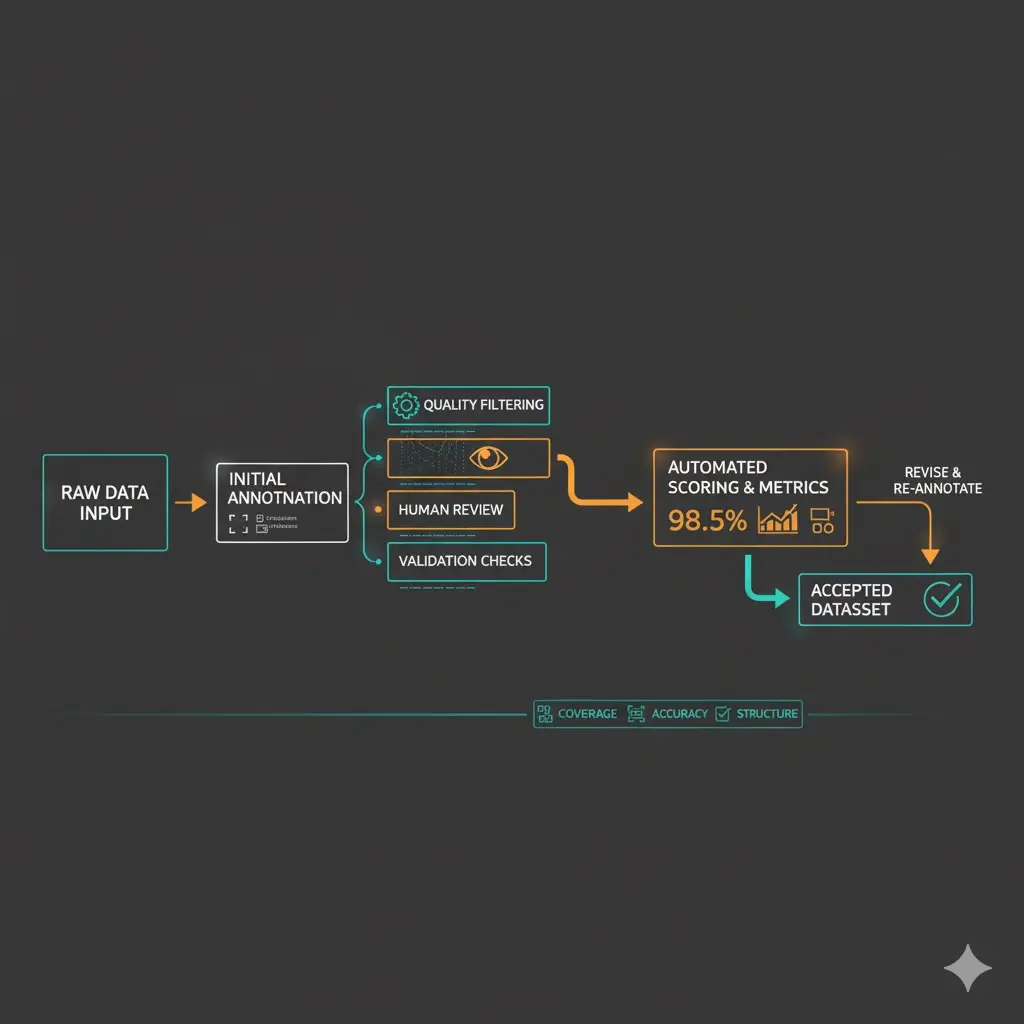
Diagram of a quality assurance annotation pipeline for OTS datasets
Here are five non-negotiables every serious US developer should look for:
Domain Alignment to Your Intended Use Case
A dataset is only valuable if it reflects the domain your model will operate in.
“Generic multimodal” does not guarantee transfer into highly specialized workflows (finance reasoning, industrial automation, robotics oversight, healthcare, legal drafting, etc.).
Structure + Annotation Fidelity
It’s not about volume — it’s about how clean and interpretable that data is.
Look for:
consistent schema
validated, auditable annotation pipelines
detailed metadata
reproducibility + version traceability
This is what separates research data vs production-grade data.
Real-World Groundedness > Synthetic Saturation
Synthetic data is extremely useful, but a dataset that becomes synthetic-heavy quickly diverges from real-world pattern distribution.
OTS datasets must be anchored in real world grounding, not just synthetic inflation.
Compliance, Licensing, and US Deployability
US AI compliance is tightening rapidly — especially as enterprise adoption (and liability) grows.
Your dataset provider must have:
clear licensing terms
clear ownership proof
provenance transparency
US-deployable compliance readiness
If legal due diligence is unclear — that dataset is already a technical risk and a regulatory risk.
Model Drift Monitoring Support
OTS data is not static — it ages.
Fast.
Vendors should provide:
recurring dataset updates
domain shift tracking
temporal refresh cycles
model drift early warning (reference: model-drift-monitoring)
Without this, your dataset is only optimized for the past — not the future.
What Strong OTS Coverage Actually Looks Like
Multiple OTS dataset modalities used for AI training
A well-designed OTS dataset isn’t limited to only one modality. The strongest providers support wide coverage — because real-world AI models don’t operate in a single domain.
ABAKA AI’s OTS library is one example of this breadth in practice — spanning:
960M+ licensed images (chart understanding, image editing, interweaved image reasoning, medical CT/MRI, face expression, arts/paintings, etc.)
120M+ licensed videos (talking head, dense captioning, game recordings, motion videos, egocentric datasets, video reasoning QAs)
Text datasets covering STEM + reasoning + coding + instruction following (Biology, Math, Chemistry, Creative Writing, Lean4, QA pairs, etc.)
Audio datasets, 3D point cloud, multimodal alignment datasets for higher-order grounded perception
SWE-Bench coding / algorithmic datasets with expert-curated + test case coverage
Multimodal image editing datasets with human verification and instruction filtering pipelines
This type of structured modality diversity directly reduces brittleness, improves transfer reliability, and lowers long-term model drift.
Bridging the Gap with ABAKA AI
ABAKA AI builds enterprise-ready multimodal datasets designed for real world automation, grounded context integrity, and long-term drift resilience. US developers use our datasets to boost downstream generalization, improve robustness, and reduce re-training cycles dramatically.
Building AI that must perform reliably — not just pass synthetic benchmarks? Explore premium production-grade data pipelines at www.abaka.ai
What's your data bottleneck this quarter?
Missing data
We collect it.
Messy data
We label it.
No time
We have itOff-The-Shelf.
Pick the closest fit, we'll take the call from there.